
第四范式 2025年10月30日 继上月发布“虚拟显存”技术引发行业对GPU资源灵活分配的关注后,范式智能近日再次发布GPU动态调度新进展——基于Kubernetes动态资源分配(DRA)的GPU动态调度能力,实现对GPU算力与显存的一体化精细调度。该技术不仅是对用户关于“算力能否像显存一样动态切分”疑问的深入回应,更标志着GPU资源管理从容量扩展迈向多维资源协同调度的新阶段。知识点预置
什么是Kubernetes?
可理解为数据中心的“调度总管”,负责分配计算资源
什么是DRA?
像“灵活发牌手”,允许将一块GPU按需切分,动态分配给多个任务
什么是HAMi-Core?
由范式智能主导的开源项目,是容器内GPU的“资源控制器”,实现显存与算力的精细管控
随着Kubernetes v1.34的正式发布,其核心特性——动态资源分配(DRA)已稳定启用,标志着云原生资源调度进入更智能、更灵活的时代。在这一背景下,范式智能基于长期在AI基础设施领域的积累,率先完成了HAMi-Core与DRA的深度适配,并推出GPU动态资源驱动(DRA Driver),让GPU像CPU一样被灵活共享与调度,推动云原生算力管理体系不断完善与升级,为人工智能算力管理带来新的可能。
让GPU更灵活让算力更高效
在AI任务中,GPU是模型训练和推理的“引擎”,但长期以来,传统使用方式常导致GPU资源浪费:要么“使用不满”,要么“独占浪费”。HAMi-Core结合DRA能力,实现了GPU的动态切分与多任务并行。简单来说,不同的任务可以同时使用同一块GPU,各自占用合适的算力与显存,就像多个应用共享CPU一样高效。这带来了两大改变:
1.任务分发调度:同一个GPU节点上,由原来的串行分配变为并行调度,显著提升整体效率如果用发牌来比喻这一变化,就是从“一人发完再发下一人”到“同时发牌给所有玩家”
?过去:GPU节点上的任务必须串行执行,就像发牌员一张一张发,前一个任务不结束,后一个只能等待
现在:GPU可同时为多个任务“发牌”,实现真正的并行调度,任务等待时间大幅缩短,集群吞吐效率显著提升
2.任务申请资源:可以根据需求选择不同配置的GPU,更精细、更灵活还是用打牌来理解这个变化,就是选牌方式从“固定套餐”到“自由组合”
?过去:申请GPU像点套餐,只能选固定规格,比如申请三张数值相同的“10”牌,不管任务需要多强的算力,都只能用这一档配置
?现在:用户可以“自选组合”,根据任务需求自由搭配不同性能等级的GPU,就像同时选择“5、9、A”等不同数字的牌——量体裁衣,既精准匹配计算需求,又避免资源浪费
这种能力的提升,让GPU的调度更智能、利用更充分。在大规模集群场景下,系统复杂度明显降低,性能提升体现在调度效率和任务处理速度上,为企业带来更流畅的算力体验和更高的运维效率。
推动云原生AI基础设施的进化
HAMi-Core作为由范式智能主导贡献的开源项目,致力于提升GPU在容器化和云原生环境下的利用率。此次适配工作让HAMi-Core与Kubernetes的动态资源调度能力实现了结合,让算力资源的申请、分配和释放都能通过标准化方式自动完成,大幅降低了使用门槛。这一成果不仅体现了范式智能在AI基础设施层面的技术深耕,也展示了其对开源生态的持续投入。
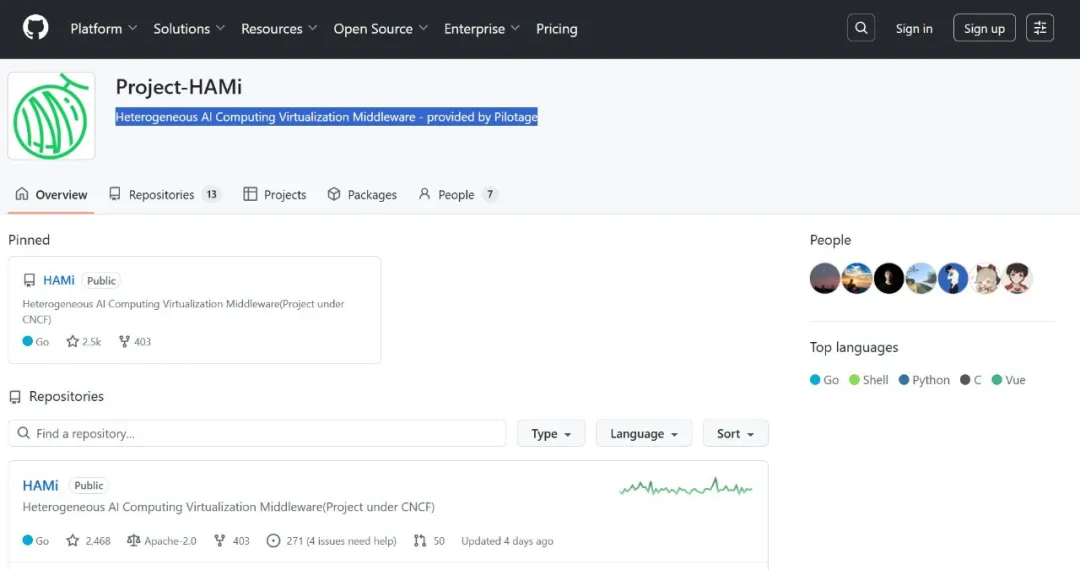
开源共建释放更大的创新力
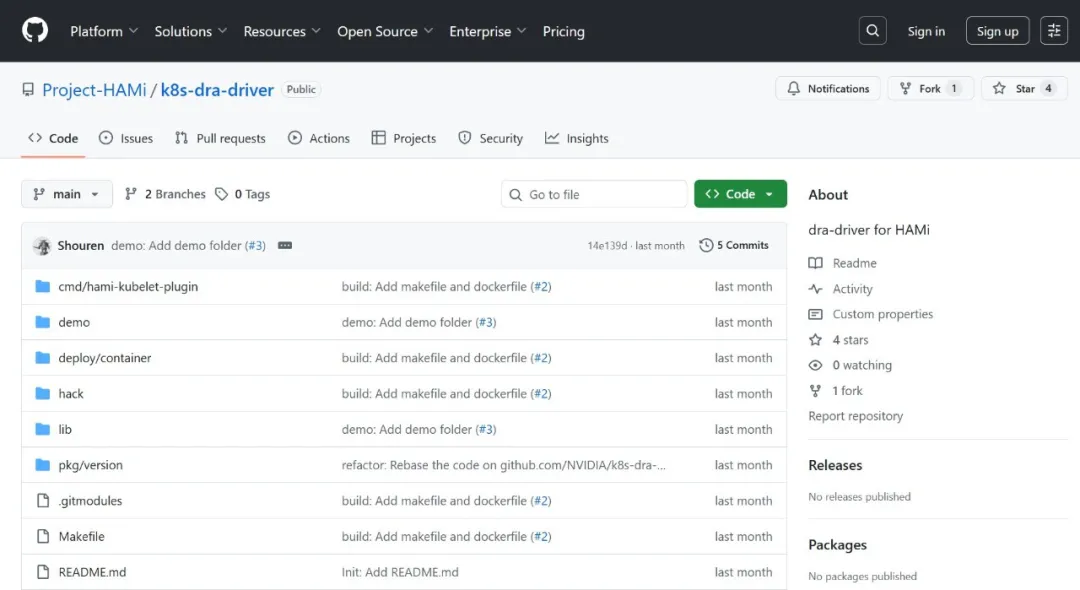
目前范式智能已将该演示项目开源至GitHub(Project-HAMi/k8s-dra-driver),并将与HAMi社区持续推进相关特性和生态建设,欢迎更多开发者和企业参与共建,共同推动GPU调度技术走向更智能、更开放的未来。
我们相信:算力的自由调度与高效利用,是推动AI普惠化的重要基石。我们将持续致力于AI基础设施的智能化与标准化,帮助更多企业以更低的成本、更高的效率,释放AI的真正价值。







CopyRight@2010-2026 中金网 All Right Reserved
中金财讯:关注全球财经动态把握市场最新脉动!










